Acceleration of Anomaly Detection in Blockchain Using In-GPU Cache
Morishima S, Matsutani H. Acceleration of anomaly detection in blockchain using in-GPU Cache[C]. international conference on big data and cloud computing, 2019: 244-251.
引言
区块链的不可篡改特性带来安全性的同时,由操作失误或密钥被盗造成的欺诈交易同样无法取消,因此产生的非法交易可能造成危害。可能的对策是即时的发现非法交易,从而在确认前纠正。
Pham等人提出一种基于K-means聚类,马氏距离和局部离群因子的区块链异常检测方法,利用该方法对比特币网络历史交易中的异常交易做了检测,但可通过特定特征量和算法检测到的异常交易是有限的,实际实施需要通过改变特征量和算法来重复异常检测,计算量大,计算时间长,该文使用了GPU加速异常检测,减少检测时间。
T. Pham, S. Lee, “Anomaly Detection in Bitcoin Network Using Unsupervised Learning Methods”, Compution Research Repository, vol. abs/1611.03941, pp. 1-5, Nov. 2016.
我们不关注如何使用GPU加速异常检测,关心的是使用了什么方法进行异常检测,因此该文大部分都会略过
特征量提取
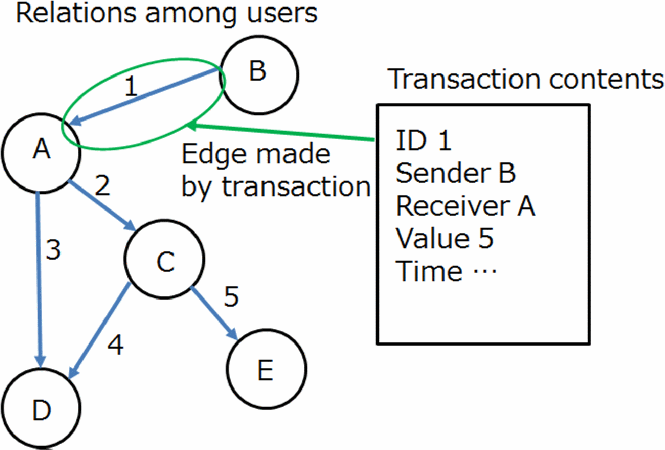
Pham等人提出的方法使用图来代表以用户为中心的交易流,如下图所示,用户是顶点,交易是边,当B向A发起交易时,会创建一条B到A的边,随着交易增加,边也随之变多,图结构变复杂。
该图用于提取每个区块链用户的特征量,例如,顶点入边的数目是收入交易的数目,出边的数目是支出交易的数目,Pham使用收入交易数目、支出交易数目、平均收入金额、平均支出金额等六个特征量进行异常检测,此外还使用了K-means聚类、马氏距离和局部离群因子三种异常检测算法。采用基于用户图的方法,对比特币网络中两期盗窃案件做了分析。但,即使检测到了异常交易,也很难判断是否真的是欺诈交易,因为大部分盗窃的具体信息并不公布。
K-means异常检测
该文使用了相同的方法提取特征量,但异常检测方法使用了K-means聚类。K-means本身是用来将大量数据分类成簇的,当使用K-means进行异常检测时,如果用户特征量距离聚类中心较远,则被视为异常,当簇的数量为K时,使用K-means聚类进行异常检测的步骤如下:
- 初始聚类被随机地分配给每个顶点的特征量向量
- 计算聚类中心
- 计算每个顶点特征量与聚类中心的距离,然后划归最近的聚类中心的簇
- 重复2,3步直到收敛,完成聚类
- 计算顶点特征量与聚类中心的距离,超过阈值则为异常
 支付宝
支付宝 微信
微信