研究记录14-重新实验及实验流程优化
我们对之前的实验流程做了进一步的优化,并且对添加恶意行为检测后的系统进行了进一步的性能测试。
1. 实验流程优化
上一次实验我们搭建 Quorum 私链网络是采用从零开始的方式,从 genesis.json 文件开始,手动编辑配置文件、创建节点、最后组建网络,不仅耗费时间,而且一旦错误就要重新开始,浪费了大量无意义的精力。另外,我们还需要一个区块链浏览器可视化网络、区块、交易和合约的状态,与智能合约的交互也需要优化,虽然 Truffle 集成了合约的部署和测试工作,但依然存在一些不足,国内也无法使用 truffle init 命令。
针对以上问题,结合 Quorum 社区的最新进展,我们本次调整了实验方案所使用的工具和手段:
- 使用 Quorum Wizard 命令行工具快速建立 Quorum 网络;
- 使用 Cakeshop 可视化区块链和智能合约状态;
- 使用 Remix + Quorum Plugin for Remix 的组合部署合约及与合约交互;
最后,我们对一些注意事项进行说明:
- Quourm Wizard 建立网络有 Bash 、 Docker-compse 和 kubernete 三种可选方式,我们使用第一种,但会尝试一下第二种;
- 之前在树莓派中建立区块链账户表示物联网网络和设备,但树莓派放在了实验室,由于疫情原因无法拿到手,因此本次建立一个 7 节点的私链网络,挑选一个节点代表物联网网关,然后建立一个新的账户表示设备,从而进行实验。
最后,确定本次方案时还有一些备选方案,比如 Epirus-free 也是一个可用的 Quorum 区块链浏览器,但结构比较简单,展示的参数也比较少,而且我们测试的时候迟迟无法加载出来数据,因此不选用。
quorum-maker 是一个一体化方案,可以快速建立基于 Docker 的 Quorum 网络,并提供一个区块链浏览器查看区块链和合约状态,各方面的功能都足够晚上,唯一的问题是对 IBFT 共识的支持还处在开发阶段,暂时不可用,因此我们只能选择上述多个工具组合的方法完成本次实验。
1.1 环境准备
Win10 Home Edition 不支持 Docker,且实验中涉及的组件比较多,我们决定使用虚拟机来启动一个 Linux 环境。另外,方案中的几个工具对依赖的要求如下:
- Quorum Wizard:
- 基于 Bash 建立网络:如果需要隐私管理器,需要 Java 环境
- 基于 Docker Compse:需要 Docker 和 docker-compose
- 基于 Kubernetes:需要 Docker、kubectl 和 minikube
- Cakeshop:需要 Java 8+ 及 Node.js
- Geth 提供了接口供 Golang 使用来进行账户管理和合约监听,因为实验测试有可能用到,我们安装 Golang
根据说明,我们开始准备实验环境
安装 VMware Workstation 15 Pro,输入批量许可激活,建立 Ubuntu20.04 系统的虚拟机,分配内存 4G(有条件应为8G,这里是因为电脑配置比较低,一共只有8G,再多发生内存交换的概率比较大)、硬盘100GB。
进入 Ubuntu 20.04,更新系统,设置语言
安装git、golang、Java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21# 安装git $ sudo apt install -y git $ git version git version 2.25.1 # 安装golang $ sudo apt install -y golang $ go version go version go1.14.4 linux/amd64 # 安装 JRE $ sudo apt install default-jre $ java -version openjdk version "11.0.7" 2020-04-14 OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1) OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing) # 安装JDK $ sudo apt install default-jdk $ javac -version javac 11.0.7安装 Node 和 npm,由于直接安装后在使用 npm 全局安装包时会出现权限错误,因此使用 Node.js 版本管理工具 n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16$ sudo apt install curl $ curl -L https://git.io/n-install | bash # 重启终端 $ n lts installing : node-v12.18.0 mkdir : /home/shuzang/n/n/versions/node/12.18.0 fetch : https://nodejs.org/dist/v12.18.0/node-v12.18.0-linux-x64.tar.xz installed : v12.18.0 (with npm 6.14.4) # 更新 npm 到最新,顺便测试全局安装 $ npm install -g npm@latest /home/shuzang/n/bin/npm -> /home/shuzang/n/lib/node_modules/npm/bin/npm-cli.js /home/shuzang/n/bin/npx -> /home/shuzang/n/lib/node_modules/npm/bin/npx-cli.js + npm@6.14.5 updated 5 packages in 16.718s(可选)docker 和 docker-compose
1 2 3 4 5 6 7 8 9 10 11 12 13 14# 安装 docker CE $ curl -fsSL get.docker.com -o get-docker.sh $ sudo sh get-docker.sh --mirror Aliyun # 启动 docker CE $ sudo systemctl enable docker $ sudo systemctl start docker # 建立 docker 用户组并将当前用户加入 docker 组,这样就不需要 root 权限了 $ sudo groupadd docker $ sudo usermod -aG docker $USER # 测试安装 $ docker run hello-world # 安装 docker-compose $ sudo curl -L https://github.com/docker/compose/releases/download/1.25.5/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose $ sudo chmod +x /usr/local/bin/docker-compose
1.2 建立测试网络
全局安装 quorum-wizard
| |
运行向导,建立测试网络,-v 参数用于输出日志记录。
| |
在向导执行页面选择了运行 Cakeshop 的情况下,不需要自己再去安装 Cakeshop,可以直接启动。
| |
此时浏览器打开 http://localhost:8999 页面,可以看到网络情况
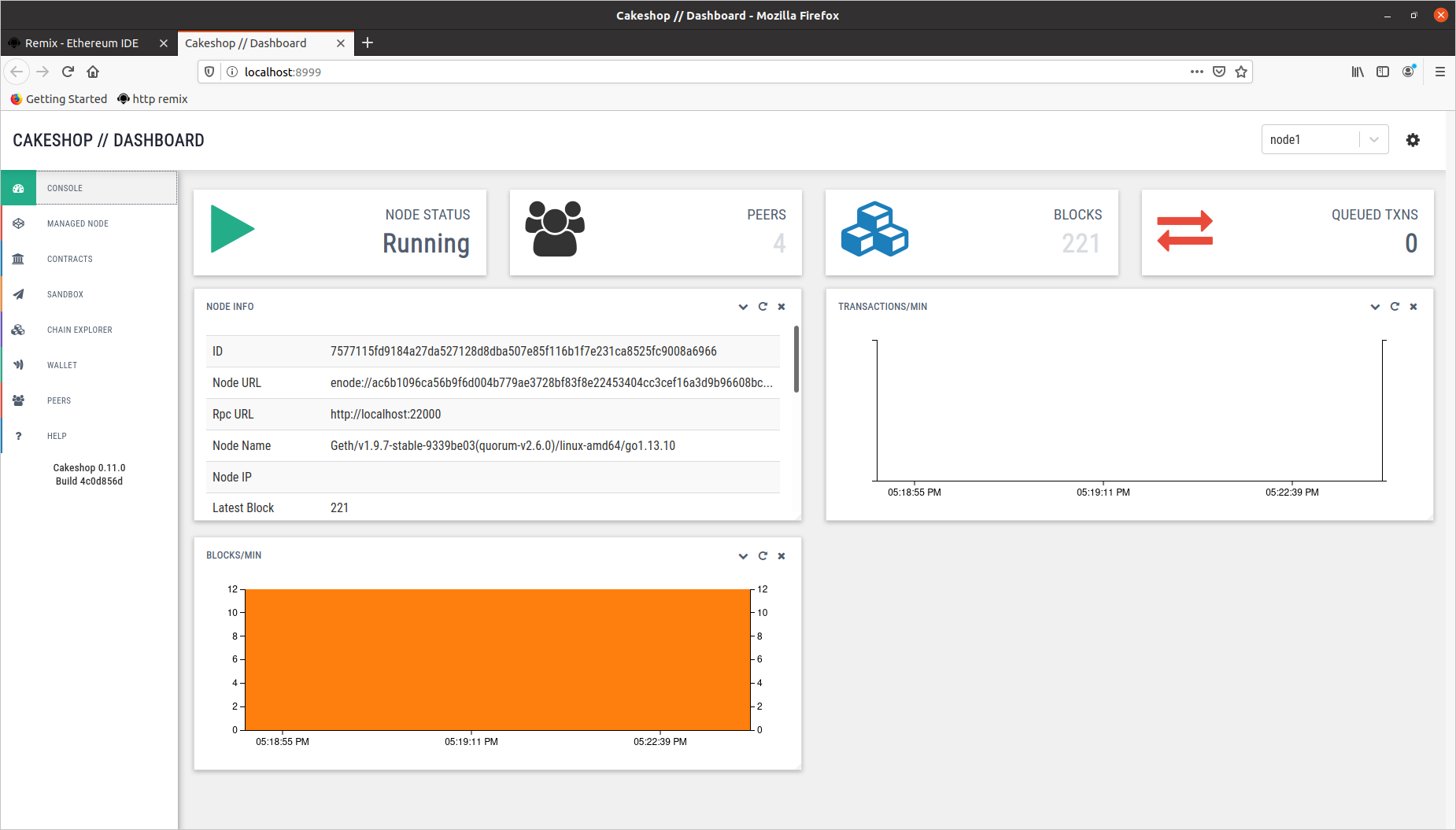
1.3 Remix 部署和交互说明
浏览器打开 Remix IDE (保证是 http 页面),点击左侧 Plugins(插件)标签页,搜索 Quorum Network,点击 Activate 激活插件。

在左侧标签栏寻找激活的插件,图标为 ![]()
我们上面运行的网络各节点的 url 分别为
| 节点 | url |
|---|---|
| Node1 | Quorum RPC:http://localhost:22000 Tessera:http://localhost:9081 |
| Node2 | Quorum RPC:http://localhost:22001 Tessera:http://localhost:9082 |
| Node3 | Quorum RPC:http://localhost:22002 Tessera:http://localhost:9083 |
| Node4 | Quorum RPC:http://localhost:22003 Tessera:http://localhost:9084 |
输入 Node1 的 Quroum RPC 和 Tessera 的 url,点击确认,得到如下的侧面板
从 Github 导入我们的合约
Quorum-Remix 插件使用 Remix 的 Solidity 编译器的结果,所以在 Remix 编译后的合约可以在Quorum插件的 Compiled Contracts 选项下找到,到时候输入参数点击部署即可,操作与 Remix 原本的 Deploy 选项卡完全一致。
最后,运行 .stop.sh 脚本可以停止所有的 quorum/geth 和 cakeshop 实例。
如果我们编写了交互用的 js 脚本,假设脚本名为 test.js,可以使用如下命令执行
| |
有输入参数的情况下,可以使用 Bash 、Python 或 Go 有选择的批量执行脚本。
值得注意到是,我们上述没有使用隐私管理器,但这是 Quorum 的一个最重要的特性。
1.4 错误排查记录
2020.06.08
Remix 无法显示所有插件,因此无法使用 Quorum Network 插件连接 Quorum 网络,经排查,为网络原因,连接手机开的热点后即可看到所有插件,深层原因未知。
2020.06.09
合约编译返回错误 Uncaught JavaScript exception: RangeError: Maximum call stack size exceeded.
调用栈溢出,猜测可能是虚拟机内存分配不足,在宿主机中使用 Remix 通过局域网 IP 地址连接
宿主机浏览器无法访问 http 连接,换用 Firefox 或者使用 Remix-IDE 桌面版本都无法访问
考虑到此时 Remix 与 后台 Quorum 网络拆分,尝试使用 WSL 子系统,并使用 npm 安装 remix-ide
WSL 对 npm 支持不友好,普通用户和 root 用户权限全部被拒绝,所有包都无法安装
尝试在 win10 本地使用 npm 安装 remix,依赖过多,安装无法完成
重新尝试解决 win10 系统下无法访问 http 网页的错误,关闭防火墙不起作用,恢复 hosts 文件起作用,经确认,无法访问 http 网页是因为 hosts 文件被修改
重新尝试虚拟机的 Ubuntu 系统编译智能合约,Chrome 浏览器失败,Firefox 浏览器成功,确认不是因为内存分配不足。
2. 性能测试
根据上篇最后一小节的分析,性能测试分为三部分:隐私合约及交易测试,访问控制系统测试和恶意行为检测部分的测试。
性能测试的指标如下所述:
访问控制系统
合约部署和重要操作的Gas 消耗:Gas 消耗可以通过 Remix 测试的时候获取,虽然对于 Quorum 而言,Gas 消耗并无太大意义,因为并不会真正消耗掉,而是会被返还,但对于大多数基于以太坊的方案来说,Gas 消耗意味着实际的金钱消耗。另一方面,Gas 消耗一定程度上能反映合约的体积。
一些重要的合约交互需要的时间:当然,首先我们应当确定,测量得到的时间中,是合约执行的时间占主要地位,还是区块链网络的同步时间占主要地位,只有前者得到的结果具有实际的意义。
属性及策略的增加对访问时间产生的影响。由于访问决策的逻辑,对策略的判断基本是遍历的方式,这意味着属性和策略的增加可能会使访问时间延长,我们应测量并讨论这一影响的后果及与其它方案的比较。
不同的方案对区块链造成的存储压力。由于方案设计的不同,区块链受到的存储压力不同。即,有些方案需要部署更多的合约,存储更多的数据,从而导致区块链的快速增长。我们需要测量完成同样多的访问不同方案的区块链增长速度,一个可度量的参数是单位时间增加的区块数。
不同方案的吞吐量。实际上,吞吐量更大程度上受区块链选择的影响,不过可以作为我们的一个测量方向。
恶意行为检测
需要验证奖励、惩罚、容忍、报警四大功能。
惩罚就是阻塞时间到期之前不允许方案,是一个功能测试;奖励和容忍是一体的,由于奖励的存在,某些不太重要的恶意行为可以被容忍而不会触发惩罚;报警是触发恶意行为时及时向管理员反馈,只要持续检测合约发送的事件即可。
我们可以得到的数据值包括:某个行为发生的时间、行为描述、信誉值(包括奖励和惩罚两部分都可以知道)、做出惩罚的时间、惩罚计算出的阻塞时间大小。我们可以得到以下结果
- 信誉值随时间的变化;
- 检测到恶意行为的概率(与容忍相关);
- 阻塞时间的变化;
- 同样多的请求,恶意行为被阻止的百分比;
恶意行为检测需要大量的输入,包括访问控制系统中各种不同类型的行为,各行为产生的时间等,但是,还有一些注意事项:
- 实际环境中,不同的行为产生的概率可能不一致,例如更新操作多一点,而注册和删除操作少一点,访问操作最多等;
- 不同的行为间有先后关系,例如,更新、删除操作都必须在注册操作之后,访问操作也需要测量所依赖的属性已存在;
- 新增、更新或删除的属性或策略,可能会影响访问结果;
- 访问时间的随机性会决定「短时间频繁请求」这一恶意行为是否会产生;
我们将输入参数定义为一个文件,文件包括两列,第一列是行为产生的时间(应当随机产生),第二列是行为类型,根据行为类型的不同调用不同的脚本,从而完成这一行为。
对上述注意事项的解决办法是:
- 访问允许或拒绝依赖于已定义的属性和策略,这些属性和策略恒定不会被更新和删除,而所有新的新增、更新、删除操作是额外的;
- 如果某种行为产生时依赖的属性或策略不存在,比如更新时发现属性还未定义,那么跳过它执行下一个行为;
- 不同行为以等概率的方式随机生成;
- 我们以生成时间间隔的方式产生随机的时间;
2.1 隐私功能测试
隐私合约及交易是 Quorum 自带的功能,本身不是我们实现的,因此测试只是验证该功能是否启用。合约的部署与交互使用了 Quorum for Remix 插件,该插件在 Remix 的插件列表中可以找到。测试用的合约如下
| |
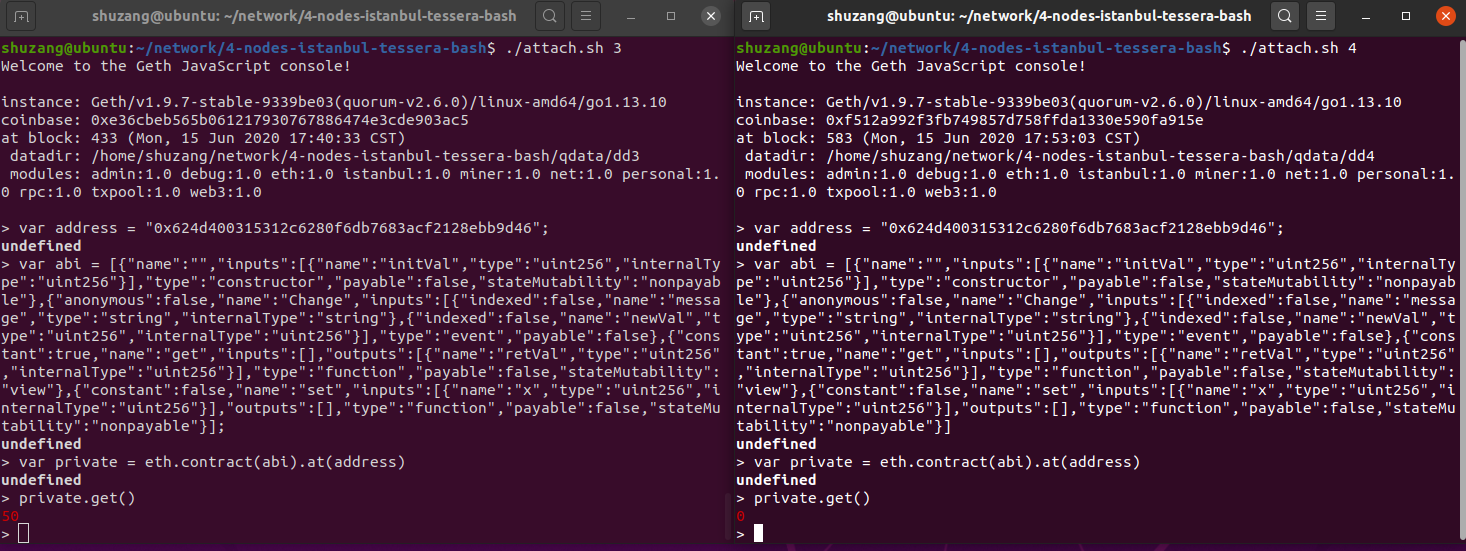
我们令Node2 代表农场,Node3 代表超市,假设农场部署了一个私有存储合约,状态只能被超市查看。农场部署合约传入一个初始值 50,理论上,Node2 和 Node3 可以通过调用 get() 函数获取到该数据,其它的节点无法查看该数据。
因此我们分别进入 Node3(超市) 和 Node4 的 Geth console 进行验证,如下图所示,左侧是 Node3,可以查看合约状态并获取数据,右边是 Node4,无法查看合约状态,也无法获得数据。
从 Cakeshop 区块链浏览器可以更清楚地看到两种情况
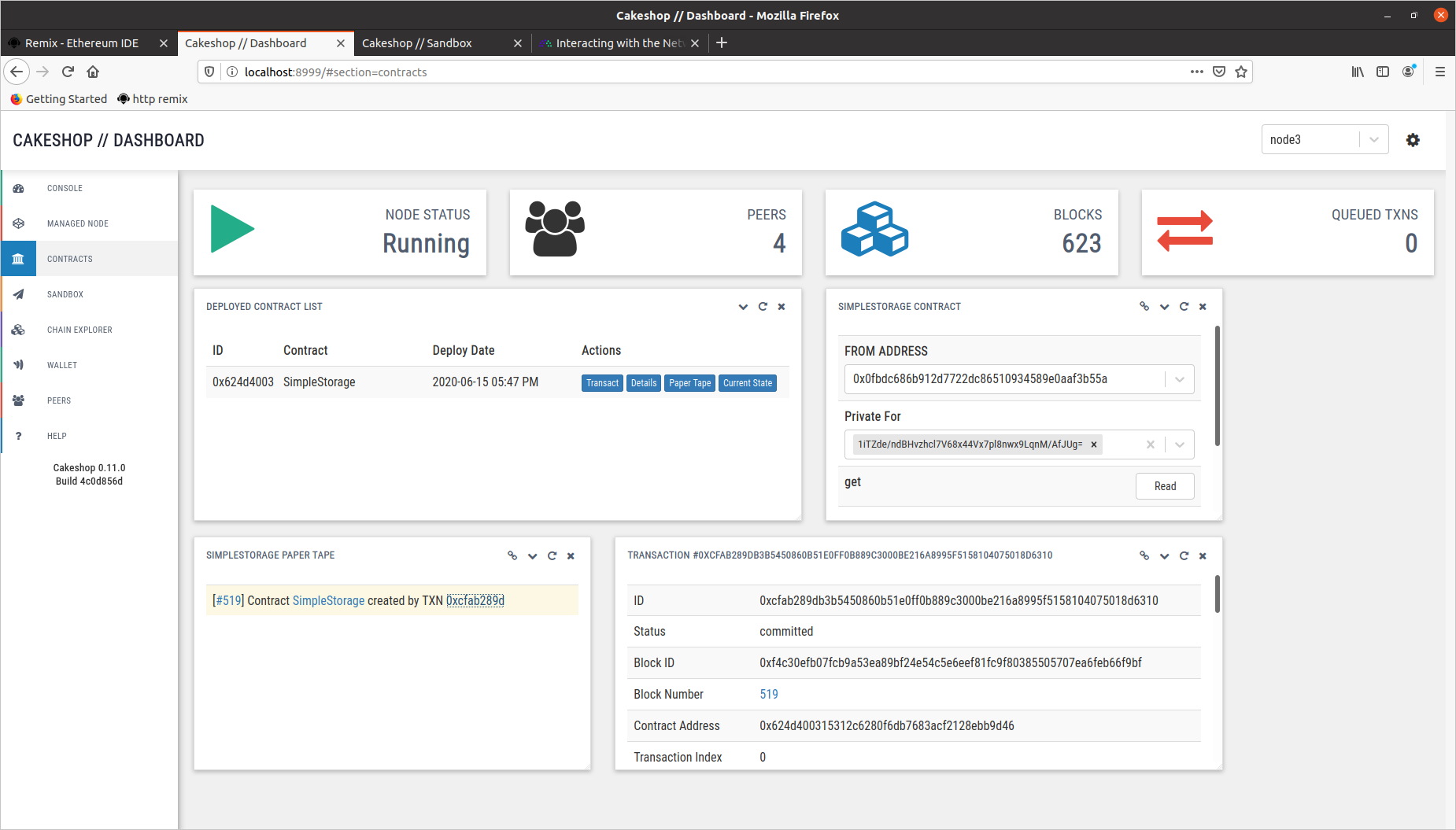
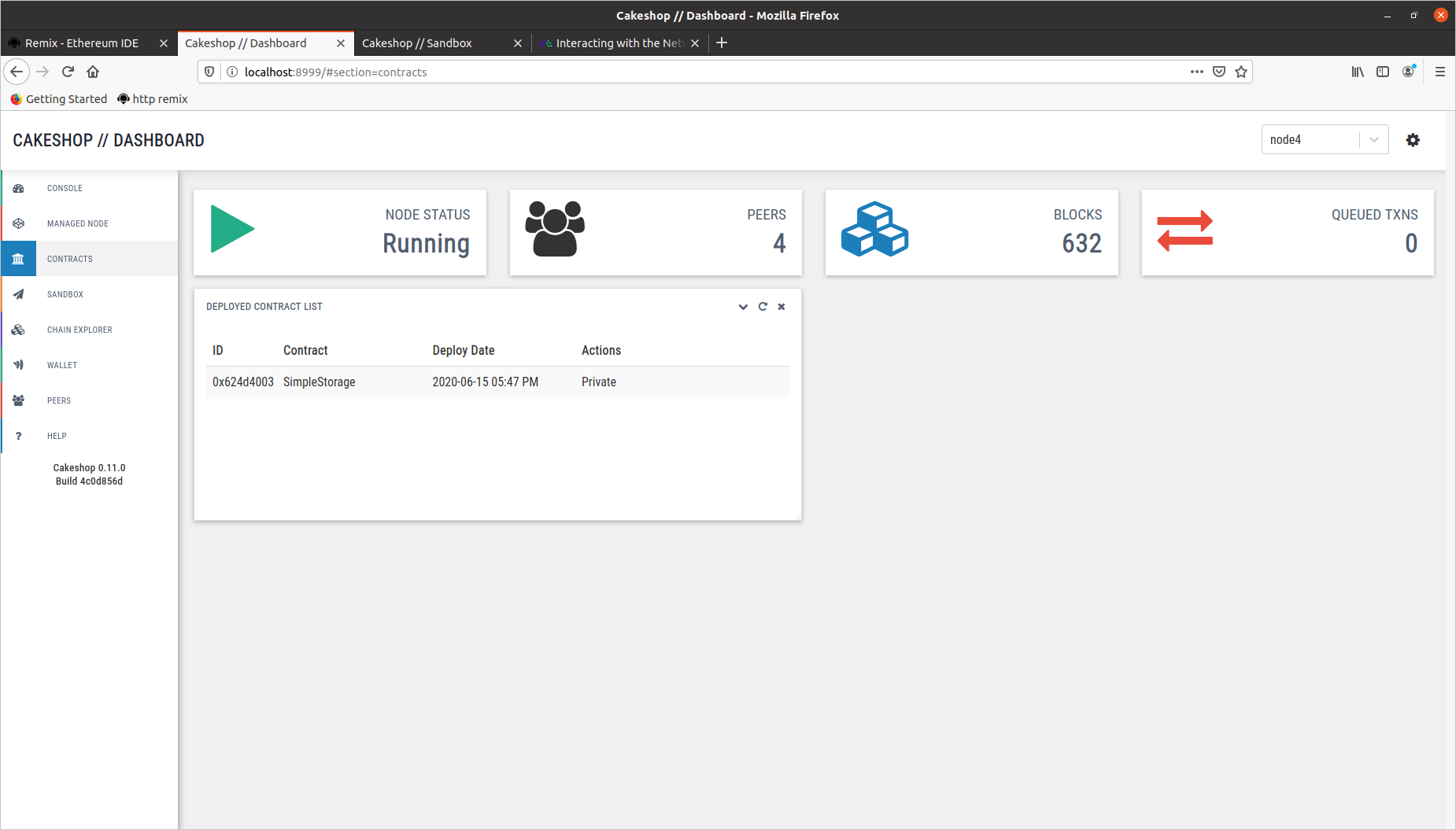
2.2 访问控制时间测试
主要测试参数为完成一次访问控制的时间,期间我们要确认信誉系统的加入是否对访问控制时间有影响,以及不同的访问控制方案是否对时间有影响。
2.2.1 测试准备
第一部分隐私功能测试时使用了 Quorum for Remix 插件,由于该插件在 Remix 中无法返回执行结果,在非隐私交易时不具备优势,因此访问控制系统时间测量的预准备工作,包括合约部署和交互,使用了 Remix 自己提供的 Deploy and Run 插件,主要利用 Web3 Provider 来连接 Quorum 网络进行操作。连接端口在 geth 启动时已默认打开,我们使用的三个节点对应的 Web3 端口如下
- Node1:22000
- Node2:22001
- Node3:22002
另外,我们单独安装 Web3.js 并编写 JS 代码来进行访问控制
| |
为了获取足够样本进行分析,我们要进行大量的访问控制测试并获取每次的访问控制时间,先后使用的方案有三种,我们会阐述前两种方案不可行的原因
在 JS 脚本中设立循环,使用 setInterval() 函数延时固定的时间发起访问控制,得到的结果中,初次访问控制的时间为 10ms 左右,其后迅速减少,在 1ms 和 2ms 左右浮动。查询后发现,Javascript 中 setInterval 函数的实质是每隔一段时间向任务队列中添加回调函数,开始执行的时间是不确定的,最后导致了时间统计的不确定性。
使用 Shell 脚本编写循环,在循环中调用 JS 代码,然后使用 sleep 函数设置延时,访问时间的获取是通过 Javascript Date 对象的 getTime 方法,在发起访问控制前获取了一次时间,在获得结果后获取了第二次时间,然后求其差值。最后得到的结果发现,访问控制时间受发起访问的时机影响,呈周期性波动,也受 CPU 占用率的影响,占用率越高时间越短,显然这一结果是不合理的。关于这一次尝试的结果,可以查看第 2.5 节。
使用 Linux time 命令获取执行时间,我们猜测周期性的出现是系统中其它进程的影响,为了排除它们的影响,我们使用了 Linux 的 time 命令。当测试一个程序或比较不同算法时,执行时间是非常重要的,一个好的算法应该是用时最短的。所有类UNIX系统都包含time命令,使用这个命令可以统计时间消耗。例如:
1 2 3 4 5 6[root@localhost ~]# time ls anaconda-ks.cfg install.log install.log.syslog satools text real 0m0.009s user 0m0.002s sys 0m0.007s输出的信息分别显示了该命令所花费的real时间、user时间和sys时间。
- real时间是指挂钟时间,也就是命令开始执行到结束的时间。这个短时间包括其他进程所占用的时间片,和进程被阻塞时所花费的时间。
- user时间是指进程花费在用户模式中的CPU时间,这是唯一真正用于执行进程所花费的时间,其他进程和花费阻塞状态中的时间没有计算在内。
- sys时间是指花费在内核模式中的CPU时间,代表在内核中执系统调用所花费的时间,这也是真正由进程使用的CPU时间。
shell内建也有一个time命令,当运行time时候是调用的系统内建命令,应为系统内建的功能有限,所以需要时间其他功能需要使用time命令可执行二进制文件
/usr/bin/time。所以我们使用/usr/bin/time获取执行访问控制的时间,然后计算 user 和 sys 的和,得到的结果就是访问控制实际执行所花费的 CPU时间。
参考:Linux time命令
我们首先建立 xtime 文件(无后缀),将如下内容写入
| |
-f 参数用于指定输出格式,-f 后面的几个参数说明如下
| 参数 | 描述 |
|---|---|
| %e | real时间 |
| %U | user时间 |
| %S | sys时间 |
| %P | 进程所获取的CPU时间百分百,这个值等于user+system时间除以总共的运行时间。 |
然后建立 shell 脚本,命名为 runscript.sh,内容为
| |
其中,requester_legal.js 是完成访问控制的 JS 文件,接下来授予 xtime 和 runscript.sh 执行权限
| |
执行 Shell 脚本之前,我们需要先解锁发起访问的账户,由于我们会一次性进行 500 次测试,每次间隔 5 s,因此一次性将账户解锁 2500s 以上,这里我们设置 4000s。解锁相应账户的命令如下,第二个参数为密码,第三个参数为时间。
| |
执行 runscript.sh 脚本即可开始测试
| |
所有的时间会输出到终端,如上面的格式,第一列是用户态运行时间,第二列是内核态运行时间,第三列是实际运行时间,最后一列是进程所获取的CPU时间比例。
注1:设备发起访问控制时,应当首先获取目标设备绑定的访问控制合约地址,该地址可以根据设备账户在管理合约中查询得到,但这里我们为了测试方便,选择预定义,而不是每次去查询。
注2:所有的代码文件都放在 github 仓库中。
2.2.2 无信誉系统
完整的方案中包含 MC(管理合约)、ACC(访问控制合约)和RC(信誉合约),现在,我们将 RC 从系统中移除,并删除 MC 和 ACC 中所有相关的调用。
JS 文件基本逻辑如下,可以看到,前面都是变量定义的过程,执行主体是访问控制函数,当获取到 receipt 时退出(返回的事件位于 receipt 中,可以输出确认一下,正式测试时为了输出结果的格式可以只用 receipt.status判断即可)。
| |
合约部署时得到的结果如下
| 合约 | Gas 消耗 |
|---|---|
| MC | 1958457 |
| ACC | 4128313 |
合约部署完毕后定义属性和策略,最后根据具体情况修改 JS 和 Shell 脚本,500 次访问时间的平均值为 0.62682s,最大值为 0.99s,最小值为 0.57s。
2.2.3 恶意行为检测加入
加入信誉合约 RC 后进行测试,部署合约、注册设备、定义属性和策略。三种合约部署的 Gas 消耗分别为
| 合约 | Gas 消耗 |
|---|---|
| MC | 2512367 |
| ACC | 4749983 |
| RC | 1170616 |
注意,我们在访问控制合约初始化时设定了两次访问控制请求间隔应不少于 100s,否则会触发 Too frequent request 错误。这个设定会极大的延长我们测试的总时间,所以我们把这个时间间隔重新设定为 4s,这样 shell 脚本中的 sleep 5 就不会触发错误。
测试前解锁相应的账户
| |
500 次测试结果的平均值为 0.66736s,最大值为 2.71s,最小值为 0.55s。
2.2.4 wang的方案
在下面的论文中,wang 等利用智能合约对传统 ABAC 架构进行了实现,我们认为对比该方案和我们的方案具有较大的意义。
| |
鉴于作者没有提供源码,我们按照论文的描述进行了复现,然后在我们当前的实验平台下测试其访问控制时间,500 次测试的平均值为 0.69348s,最大值为 1.96s,最小值为 0.6s。
我们对三种情况的时间总结如下表
| 单位/ms | 无信誉系统 | 加入信誉系统 | wang的方案 |
|---|---|---|---|
| 平均值 | 626.82 | 667.36 | 693.48 |
| 最大 | 990 | 2710 | 1960 |
| 最小 | 570 | 550 | 600 |
可以看到,信誉系统的加入使得访问控制的平均时间增加了约6%,主要是因为执行访问控制时需要和信誉合约进行交互。而 wang 的方案相比于加入信誉系统的方案平均时间增加了约 4%,相对于没有信誉系统的方案增加了约 11%。
三种方案的主要区别在于合约逻辑的不同,包括循环的执行、合约间的相互调用次数,尤其是 wang 的方案合约间相互调用比较多,所以平均时间要更多。
2.2.5 意外
我们在使用 JavaScript Date对象测试时发现一个意外情况,访问时间会受发起访问的时机的影响,假设 t 为两次访问的间隔,那么区别如下
| t % 5 == 0 | t % 5 == 1 | t % 5 == 2 | t % 5 == 3 | t % 5 == 4 | |
|---|---|---|---|---|---|
| 结果趋向 | 4500ms | 3500ms | 2500ms | 6500ms | 5500ms |
三种方案都会出现如上结果,事实上,访问时间不仅收发起访问控制的时机影响,为了排除后台进程占用对时机的影响,我们特地利用程序分别使 CPU 占用保持在 50%,80%和100%重新进行了测试,不同的CPU占用率下,访问时间也不同,具体如下
| t % 5 == 0 | t % 5 == 1 | t % 5 == 2 | t % 5 == 3 | t % 5 == 4 | |
|---|---|---|---|---|---|
| CPU占用20% | 4500ms | 3500ms | 2500ms | 6500ms | 5500ms |
| CPU占用50% | 4300ms | 3300ms | 2300ms | 6300ms | 5300ms |
| CPU占用80% | 4100ms | 3100ms | 2100ms | 6100ms | 5100ms |
| CPU占用100% | 3950ms |
最后,我们特定将 CPU 限制在了单核单线程,得到的结果没有区别。
- 对合约的调用操作,分为不改变合约的状态和会改变合约的状态两种情况,这两种情况调用产生的时间消耗不同;
- 访问时间属于更改合约状态这种情况,此时,访问时间不因程序逻辑的变化而变化,意思是循环数量、合约间相互调用的数量,都不会对访问消耗时间产生影响;
- 访问通过和被拒绝属于合约逻辑问题,同样不对访问时间产生影响;
- 访问时间受网络情况影响,包括发起访问的时机和后台CPU的占用率;
2.2.6 其它
最后我们看一下更改合约状态的函数和不更改合约状态的函数执行时间是否有差别。我们写了两个关于存储的合约进行测试,合约内容如下
| |
调用的 Helper 合约具体内容如下
| |
我们调用 Storage 合约中的 store 函数查看对合约状态进行更改时的时间消耗,调用 get 函数查看不更改合约状态时的时间消耗,调用 retreive 函数查看多次调用其它合约时对时间的影响。得到的结果如下
2.3 不同方案的存储占用分析
由于不同访问控制方案的架构不同,随着物联网中用户、设备及访问请求数量的增加,区块链上存储的合约总大小增长速度不同,对区块链存储造成的压力不同。
下面是三种不同方案的合约字节码大小
| 方案 | 合约大小(bytecode 大小) |
|---|---|
| BBRAC(我们的方案) | ABDKMathQuad.sol: 885 bytes Management.sol: 77,960 bytes Reputation.sol: 102,088 bytes AccessControl.sol: 121,454 bytes |
| zhang | RC.sol: 7,735 bytes JC.sol: 17,174 bytes ACC.sol: 31,231 bytes |
| wang | Subject.sol: 23,760 bytes Object.sol: 12,431 bytes Policy.sol: 49,978 bytes AccessControl.sol: 40,086 bytes |
合约的增长关系描述如下
- BBRAC:1 个 ABDKMathQuad.sol, 1 个 Management.sol, 1 个 Reputation.sol, n 个 AccessControl.sol,n 为设备数量;
- zhang:1 个 RC.sol,1 个 JC.sol,n 个 ACC.sol,n 为 Subject-Object 数量;
- wang:1 个 Subject.sol,1 个 Object.sol,1 个 AccessControl.sol,n 个 Policy.sol,n 为用户数量,每个用户可能拥有多个设备。
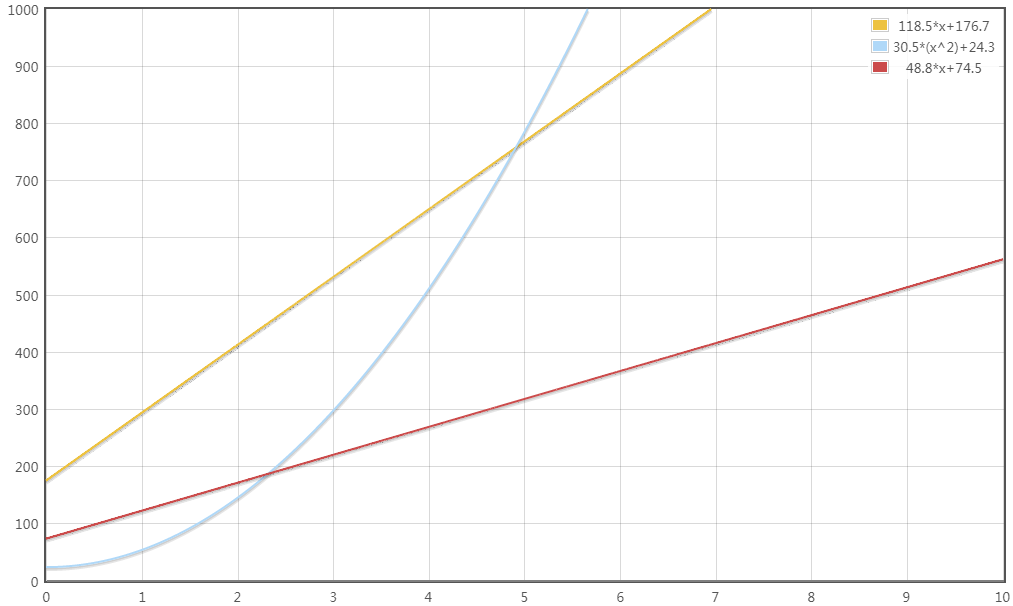
我们假设设备数量为 n,每两个设备间均会发起访问请求,即有 $n^2$ 个 Subject-Object 对,每个设备归属于不同的用户,即用户数量也为 n(便于统一 x 轴),由此得到合约大小随设备数量增长的表达式(单位为 KB):
- BBRAC:$y = 118.5n + 176.7$
- zhang:$y = 30.5n^2 + 24.3$
- wang:$y = 48.8n + 74.5$
根据表达式绘制图表如下,可以看到,zhang 的方案中合约占用的存储空间随着设备增加在快速增长,5个设备以上存储占用就高于我们的方案,wang 的方案虽然比我们的存储占用增长速率低,但是在访问时间和和合法交易的通过率上有不足,这一点我们接下来介绍。
3. 恶意行为检测测试
如上篇所述,信誉系统的测试需要发起持续不断的合约调用,具体来说,就是在随机的时间调用随机的合约函数,从而验证奖励、惩罚、容忍、报警四大功能。
随机的时间间隔使用泊松分布生成,具体方法在 另一篇文章 中介绍。在生成的随机时间点具体执行哪个合约调用,我们进行了如下考虑
首先,会影响信誉值的行为包括
| 事件 | 所属合约及函数 | 合法/恶意 | 事件编号 |
|---|---|---|---|
| Attribute add | MC:addAttribute | 合法 | 1 |
| Device manager update | MC:updateManager | 合法 | 2 |
| Device customed attribute update | MC:updateAttribute | 合法 | 2 |
| Device delete | MC:deleteDevice | 合法 | 3 |
| Attribute delete | MC:deleteAttribute | 合法 | 3 |
| Resource attribute add | addResourceAttr | 合法 | 1 |
| Policy add | ACC:addpolicy | 合法 | 1 |
| Device manager update | ACC:updateManager | 合法 | 2 |
| Resource attribute update | ACC:updateResourceAttr | 合法 | 2 |
| Resource attribute delete | ACC:deleteResourceAttr | 合法 | 3 |
| Policy delete | ACC:deletePolicy | 合法 | 3 |
| Policy item delete | ACC:deletePolicyItem | 合法 | 3 |
| Access authorized | ACC:accessControl | 合法 | 4 |
| Blocked end time not reached | ACC:accessControl | 恶意 | 0 |
| Policy check failed | ACC:accessControl | 恶意 | 0 |
| Too frequent access | ACC:accessControl | 恶意 | 1 |
| Both above two | ACC:accessControl | 恶意 | 1 |
以上影响信誉值的行为间是有先后关系的,比如,update、delete 都必须在 add 之后完成,access control 发起的条件是相关的属性和策略已定义等。如果我们完全随机的产生事件,很可能某些行为无法执行。
解决办法:忽略行为间的先后关系,因为如果存在显式的先后关系,一定会被我们定义的 require 机制给阻止,不会导致系统出错。
当确定了具体的行为,调用时如何传入参数。因为属性和策略的增删改一定会影响访问控制的结果,这样的话,访问成功还是失败完全不受我们控制。
解决办法:去除会影响结果的行为,因为同一类行为对信誉值的影响是相同的,所以每种行为我们只需要保留一个就可以。比如,合法行为中,Attribute add、Resource attribute add、Policy add 三者等价,我们只保留 Attribute add 一个行为,产生的所有 add 类行为都转换为对 addAttribute 一个函数的调用。最后我们保留下来的行为包括
事件 所属合约及函数 合法/恶意 事件编号 Attribute add MC:addAttribute 合法 1 Device customed attribute update MC:updateAttribute 合法 2 Attribute delete MC:deleteAttribute 合法 3 Access authorized ACC:accessControl 合法 4 Policy check failed ACC:accessControl 恶意 0 Too frequent access ACC:accessControl 恶意 1 为了排除仅剩的这些行为间的相互影响,我们规定,access control 将依赖于已定义好的属性和策略,新添加/更改/删除属性不会对访问结果产生影响。
每一种行为出现的概率可能是不一致的。比如,update 出现的次数可能多一点,add 和 delete 会少一点,access control 发起的频率可能是最高的。但是,在这里,6种不同的行为我们都以同样的概率来考虑,我们用 0-5 一共 6 个整数表示 6 种不同的事件,然后随机生成这个范围内的一个整数,从而确定某一时刻要调用的函数。
使用一个文本文件存放输入参数,第一列是随机时间,第二列是随机事件,利用 Bash 读取每一行,然后在具体的时间调用指定的 JS 脚本完成这一过程。记录的结果包括从信誉合约检测到的各种值。
附录 随机时间生成
我们要进行的仿真是在随机的时间执行随机的事件,这个时间就叫做事件到达时间。根据已有知识,随机的事件到达时间应该符合泊松分布,事件到达时间的间隔符合指数分布,实现时通常采用生成到达时间间隔的方式。这里的实现翻译了文章 How to Generate Random Timings for a Poisson Process,使用的语言是 Go。
事件的发生是随机的,但是从总体上看,事件以平均的速率发生,这就是泊松过程。举个例子,USGS 预计每年全世界大约发生 13000 场 4 级以上的地震,这些地震发生的时间是随机的,但一定在 13000 场左右。
统计学中有大量的函数和方程用于建模泊松过程,这篇文章介绍了一种其中一种函数,并给出了一个实现程序。
1. 指数分布
如果每年 13000 场地震,那么平均 40 分钟一场地震,所以定义变量 $\lambda = \frac{1}{40}$,称为速率参数,这是一个频率的衡量:单位时间(地震的例子里是分钟)发生事件(地震)的平均速率。
因此,接下来的问题是,下一分钟发生地震的概率是多少?下一个十分钟呢?这里有一个众所周知的函数,称为 指数分布的累积分布函数(cumulative distribution function for the exponential distribution),该函数看起来如下: $$ F(x) = 1 - e^{-\lambda x} $$
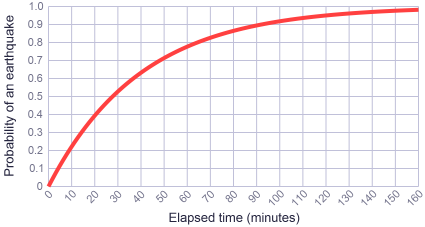
其含义是,随之时间的流逝,在世界上某个地方发生地震的可能性不断增大,这里「指数」的含义是指数衰减,随着时间流逝,不发生地震的可能性逐渐趋近于0,相应的,发生至少一场地震的可能性也趋向于1。
插入一些值,我们发现:
- 下一分钟发生地震的可能性为 $F(1) \approx 0.0247$,该值无限接近于 $\frac{1}{40}$,这个我们预设的地震频率,但不相等;
- 下一个十分钟发生地震的可能性为 $F(10) \approx 0.221$
特别的,下一个 40 分钟发生地震的可能性为 $F(40) \approx 0.632$,因此,40分钟的间隔内很可能发生地震,但不绝对。
2. 编写仿真
现在,假设我们要模拟游戏引擎或其他某种程序中地震的发生。首先,我们需要弄清楚每次地震的开始时间。
一种方法是循环,每隔 X 分钟之后,在 0 到 1 之间采样一个随机浮点值。如果该数字小于 $F(X)$,则开始地震。X 可以是一个小数值,因此可以每分钟采样几次,甚至每秒采样几次。只要随机数生成器是统一的并且提供足够的数值精度,这一个方法就会很好用。但是,如果打算以 $λ=\frac{1}{40}$ 每秒进行 60 次采样,随机数生成器需要至少18位精度,标准 C运行时库并不总是提供这一精度。
另一种方法是回避整个采样策略,只需编写一个函数即可确定下一次地震的确切时间。此函数应返回随机数,但不是大多数生成器生成的统一类型的随机数,而是以遵循指数分布的方式生成随机数。
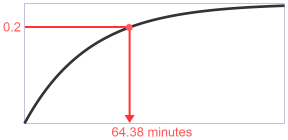
Donald Knuth 在 「The Art of Computer Programming」一书的 3.4.1(D) 一节描述了一种生成这种值的方法,只需在 y 轴上选择介于 0 和 1 之间的均匀分布的随机点,然后在 x 轴上找到相应的时间值即可。例如,如果我们从下图 y 轴选择 0.2 点,那么到下一次地震的时间将是 64.38 分钟。
由于指数函数的反函数是 ln,写这个程序很简单,其中 U 是 0 到 1 之间的随机值:
3. 实现
| |
经测试,该函数返回的平均时间确实为40
| |
实际上,Go 在 math/rand 库中本身就提供了一个生成符合指数分布的随机数的函数,叫做 rand.ExpFloat64()。实现的算法使用的是 Marsaglia 和 Tsang 在 2000 年发布的论文 The Ziggurat Method for Generating Random Variables
4. 其它仿真器
The One 是一个 opportunistic Network Environment simulator,可以设置一个仿真的 IoT 网络,参数包括网络中设备数目、带宽、通信到达时间等,使用不同的模型生成随机的运动和通信,并将过程可视化。
 支付宝
支付宝 微信
微信